RE-SAFL
A resource-efficient semi-asynchronous FL framework
Throughout the years, research in the FL field has primarily centered around the synchronous paradigm (synch FL). This implies that the server waits for all clients to finish their local training before aggregating the weights. In this paradigm, it is assumed that the central server and the client devices taking part are fully synchronous. However, as FL applications continue to scale in size and complexity, the limitations of this synchronous approach become increasingly evident, emphasizing the necessity for a more effective solution. Synch FL relies on the selection of a set of clients for each communication round, aided by client selection algorithms. These algorithms must strike a delicate balance between data heterogeneities, client availability, and computational resource constraints. The need for an unbiased client selection becomes particularly crucial as the FL ecosystem accommodates a broader range of system and data heterogeneous clients. Furthermore, the underlying assumption that all clients participating in a round will successfully complete their local training tasks and upload their model updates in a synchronized manner does not align with real-world scenarios. In practice, client failures, network interruptions, or unforeseen computational bottlenecks can disrupt the synchronized flow of FL, leading to synchronization issues and impeding model convergence.
To address challenges inherent in synch FL, researchers explored the potential of asynchronous updates, resulting in the emergence of asynchronous federated learning (asynch FL). By breaking free from strict synchronization requirements, asynch FL offers a fresh perspective on decentralized model training. In asynch FL, there is no longer a concept of a group of devices participating in each round. Instead, whenever a device is available for training, it downloads the current version of the global model from the server, perform the local model training, and upload the updated weights to the server once it has finished. The server receives updates from individual clients, and adjusts the model based on the individual updates it has received. Another difference from synch FL is that there is no predefined notion of rounds. Instead, slower clients may still send their updates later in asynch FL, but their updates may be based on outdated information. This can result in situations where fast clients are rapidly replaced by other fast clients with updated global models, while much slower clients make very little progress using the global models that are becoming out of date on the server. This phenomenon is often referred to as the ‘staleness’ issue in asynch FL.

Our study seeks to explore a basic insight that struck as “If the server can priory know about the training duration of each client upon their entry into the FL process, could we harness this information to determine an optimal aggregation time for all currently participating clients to collectively submit their weights?”. This approach offers a means to effectively manage devices prone to delays and reduce the degree of staleness in FL setup. We introduce semi-asynchronous FL, where the assumption is that a certain number of clients are available for a round. We present RE-SAFL, a resource efficient semiasynchronous FL. RE-SAFL considers varying resource capabilities of client devices. One distinguishable feature from other approaches, is the calculation of the weight aggregation time based on the maximum local computational time that each client can afford, considering its available resources. This ensures the active participation of all the device updates in the aggregation process. Furthermore, we incorporate a robust sub-model based training approach that allows slower clients to join the server aggregation without introducing staleness in the updates. Overall, our proposed RE-SAFL offers a comprehensive and effective solution for training ASR models in a distributed and semi-asynchronous manner.

The goal is to devise a strategy that ensures both resource efficiency and practicality, particularly in semi-asynchFL scenarios where mobile devices serve as clients. Our work focuses to tackle a critical challenge within this framework, which is the effective determination of the aggregation time (referred to as T). This approach is based on a careful consideration of the resource capabilities of the client devices involved in the FL process.

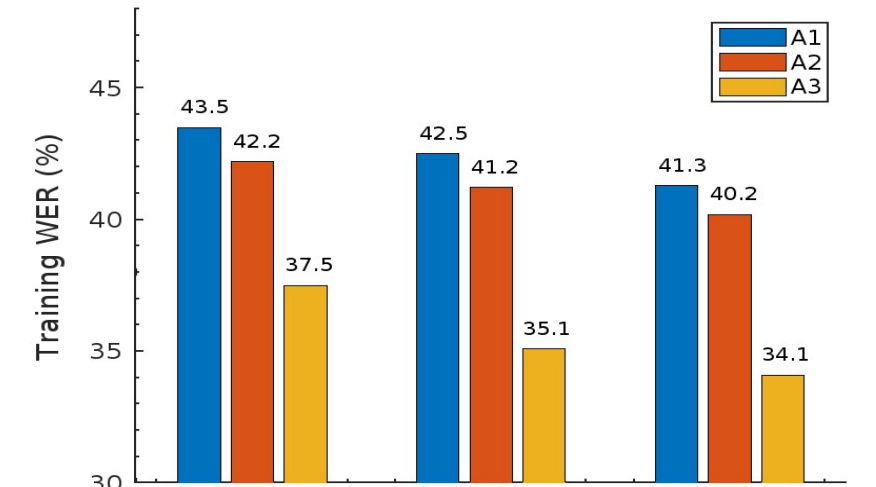
Results From the graph, it becomes evident that A3 consistently outperforms the other two algorithms across all three rounds of evaluation. This superior performance underscores the effectiveness of our RE-SAFL framework, particularly when it comes to considering the resource constraints of client devices and making informed decisions to maximize their participation in the aggregation process.
For more details, kindly have a look at our paper (Sasindran et al., 2024) and reach out to me for further details.
References
2024
- NCC
 Towards a Resource-Efficient Semi-Asynchronous Federated Learning for Heterogeneous DevicesIn 2024 National Conference on Communications (NCC), 2024
Towards a Resource-Efficient Semi-Asynchronous Federated Learning for Heterogeneous DevicesIn 2024 National Conference on Communications (NCC), 2024
