Smart client selection
A smart client selection algorithm for FL

Federated learning (FL) approach has emerged as a leading decentralized paradigm for training machine learning models, utilizing local data available on multiple client devices and thus ensuring data privacy and security. The distributed nature of FL offers immense potential for scalable and privacy-preserving model training across vast network of edge devices, such as mobile phones, and IoT devices.
One of the key challenges in FL revolves around the effective selection of suitable k clients from N available clients to participate in the training process, given their diverse hardware and specifications. This may potentially result in varying model training time among various devices as shown in the above figure. In a conventional FL setup, the server awaits model updates from all participating clients before proceeding to the next step. However, this synchronous nature of FL creates a potential bottleneck, as the overall FL process is slowed down by the variability in the training time required by each client. This variability arises from factors such as the computational power of client devices and communication delays during the transfer of model weights to the server. These delays, commonly referred to as the ``straggler effect”, are primarily caused by clients with weaker network connections or limited computational capabilities. In FL, straggler devices refer to the participating client devices that take longer to complete their computations and send updates to the central server. This delay can cause synchronization problems and slow down the overall FL process.
At present, the most common client selection approach devised in FL setups involves the random selection of k clients from a pool of N clients. This approach works well in FL when there are no straggler devices. However, excluding straggler devices and choosing only resource-rich devices for a FL round to tackle this issue can undermine the generalization capabilities of the global model and fairness in the learning process. Therefore, this chapter seeks an answer to one important question - Is it possible to cleverly (or nicely) choose the k clients such that the difference in training time among clients is minimum. Also, there is a certain randomness associated with training time taken by the client devices, and this makes the whole process challenging. For instance, the system memory might either get freed up to speed up the training time or might reduce to slowdown. There can be events where the training process itself might be removed by the operating system (OS) due to lack of memory. We observe that system resources and training time share a non-linear relationship. This idea inspired us to use tools like neural network models to understand the hidden and complex relationships between the resource capabilities with the training time requirements.
Our client selection algorithm
Considering the challenges involved in selecting the clients in FL to reduce the waiting times and efficiently managing straggler devices, we develop a resource-aware waiting time optimized client selection algorithm aimed at tackling these challenges. Our algorithm considers the resources accessible on each client device and assigns tasks adaptively based on their specific capabilities. Our approach Resource-aware waiting time optimized client selection algorithm comprises of three key phases - extraction of resource information, neural reward generation using neuralUCB, and the implementation of a resource-aware waiting time optimized algorithm.


The above results on two distinct scenarios shows the efficacy of our algorithm in reducing the waiting time issues in a heterogenous client devices FL setup. This is very important as it is very closer to the real world scenarios, where the devices will be of varying resource capabilities.

The figure depicts the findings obtained on the deployment of our Ed-Fed framework with our resource-aware client selection algorithm on multiple phones. The experiment is carried out for eight rounds on four mobile devices. In each round, client devices transmit their resource information as the context vector to the server, where the NeuralUCB-m algorithm strategically selects three devices for collaboration. The depicted results showcase a substantial decrease in WER, transitioning from an average WER of 41% to 30% after 8 rounds. We can observe that the standard deviation band also demonstrates a narrowing trend across the rounds, indicating that the performance of the global model is improving over the FL iterations. This improvement is particularly noteworthy given our waiting time-reduced client selection approach, emphasizing the practicality and scalability of our proposed framework for real-world systems
For more details, kindly have a look at our paper (Sasindran et al., 2023) and reach out to me for further details.
References
2023
- IJCNN
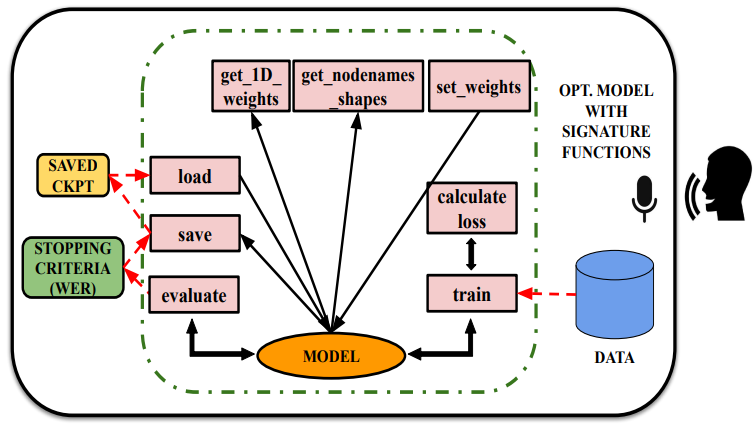 Ed-Fed: A generic federated learning framework with resource-aware client selection for edge devicesIn 2023 International Joint Conference on Neural Networks (IJCNN), 2023
Ed-Fed: A generic federated learning framework with resource-aware client selection for edge devicesIn 2023 International Joint Conference on Neural Networks (IJCNN), 2023
